Pytorch数据读取DataLoader和Dataset
1. DataLoader
DataLoader包括Sampler(用于生成索引)和Dataset(根据索引读取图片,标签)
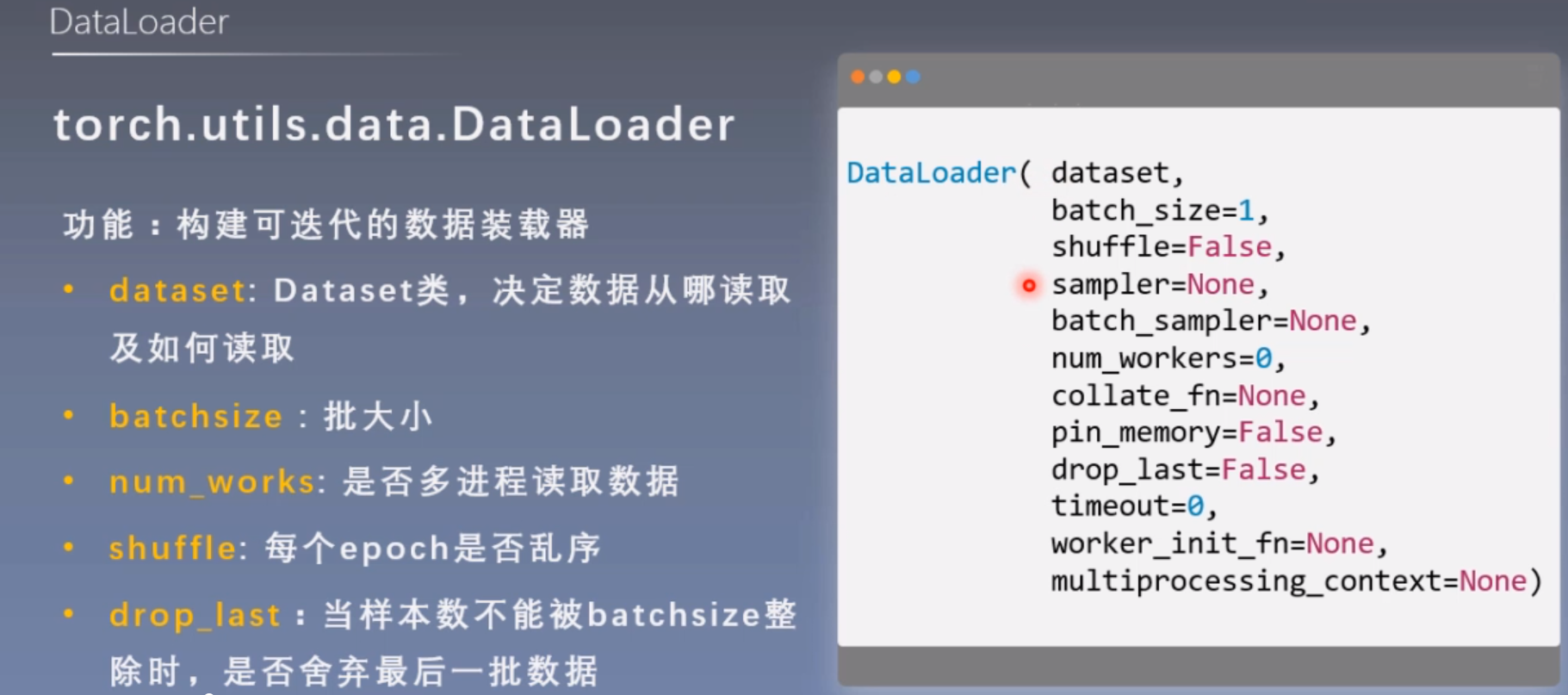
DataLoader用于构建可迭代的数据装载器
1 | torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None) |
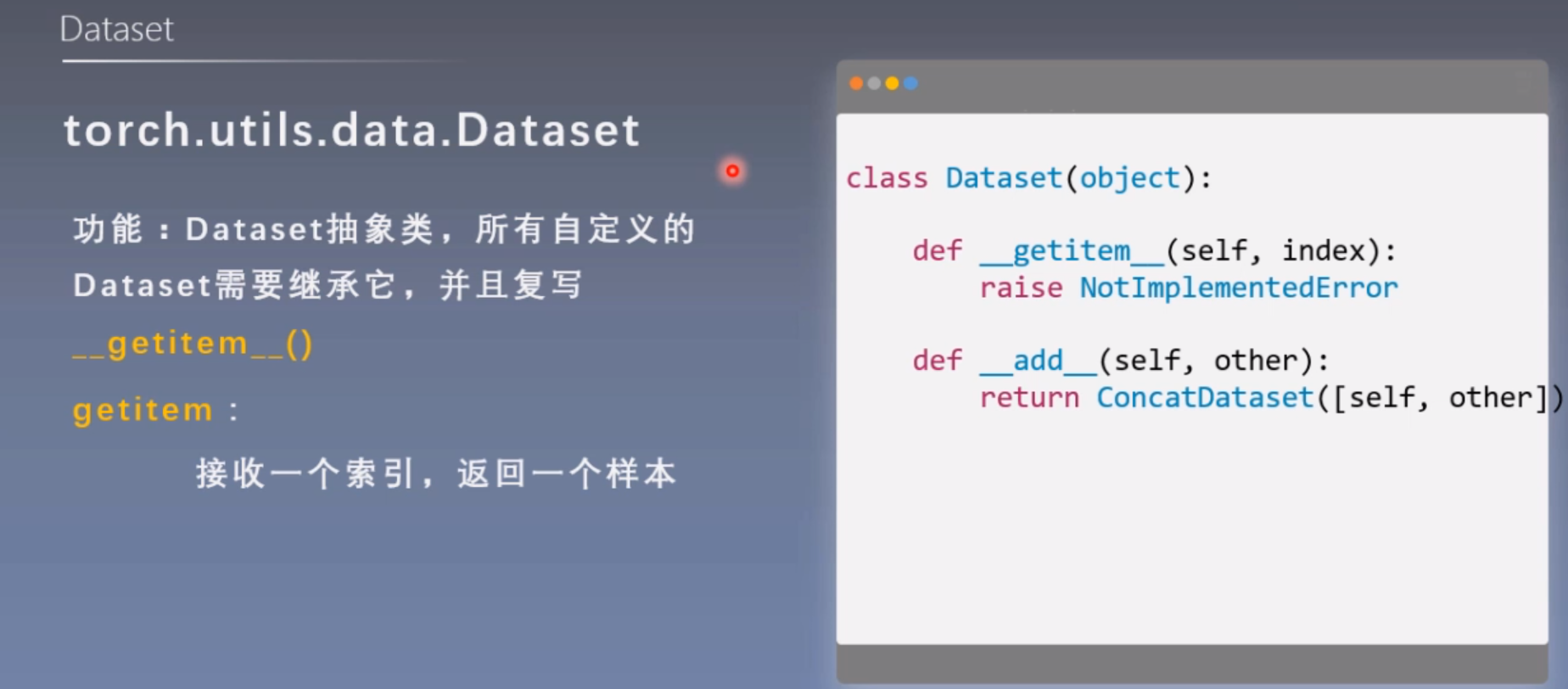
2. Dataset
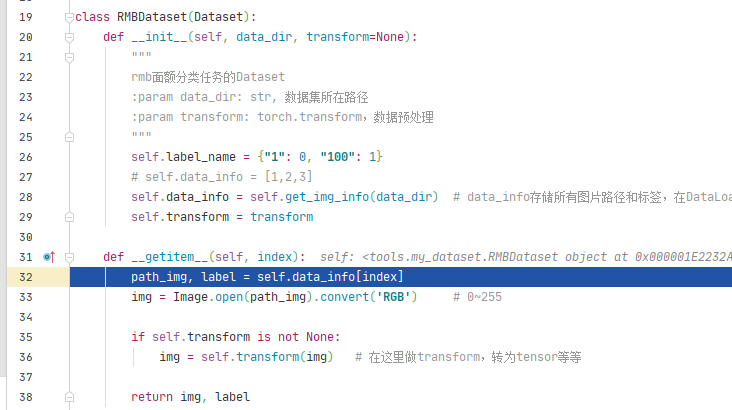
Dataset是抽象类,所有自定义的Dataset均需要继承该类,并且重写__getitem()方法。\getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。
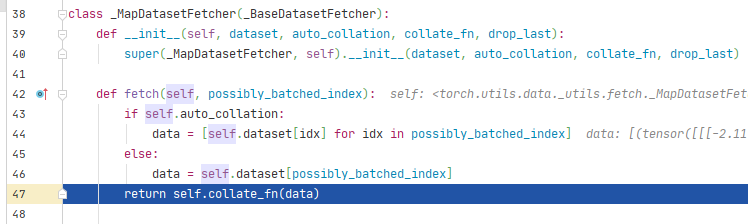
3. 读取数据过程
首先在for循环中使用DataLoader,根据是否需要多进程读取数据选择DataLoaderIter,然后通过Sampler读取index列表,在DatasetFetcher中调用Dataset的getitem方法,根据索引index从硬盘读取(图片img,标签label)列表,再通过collate_fn将列表分为batch,batch由图片img列表和标签label列表组成。
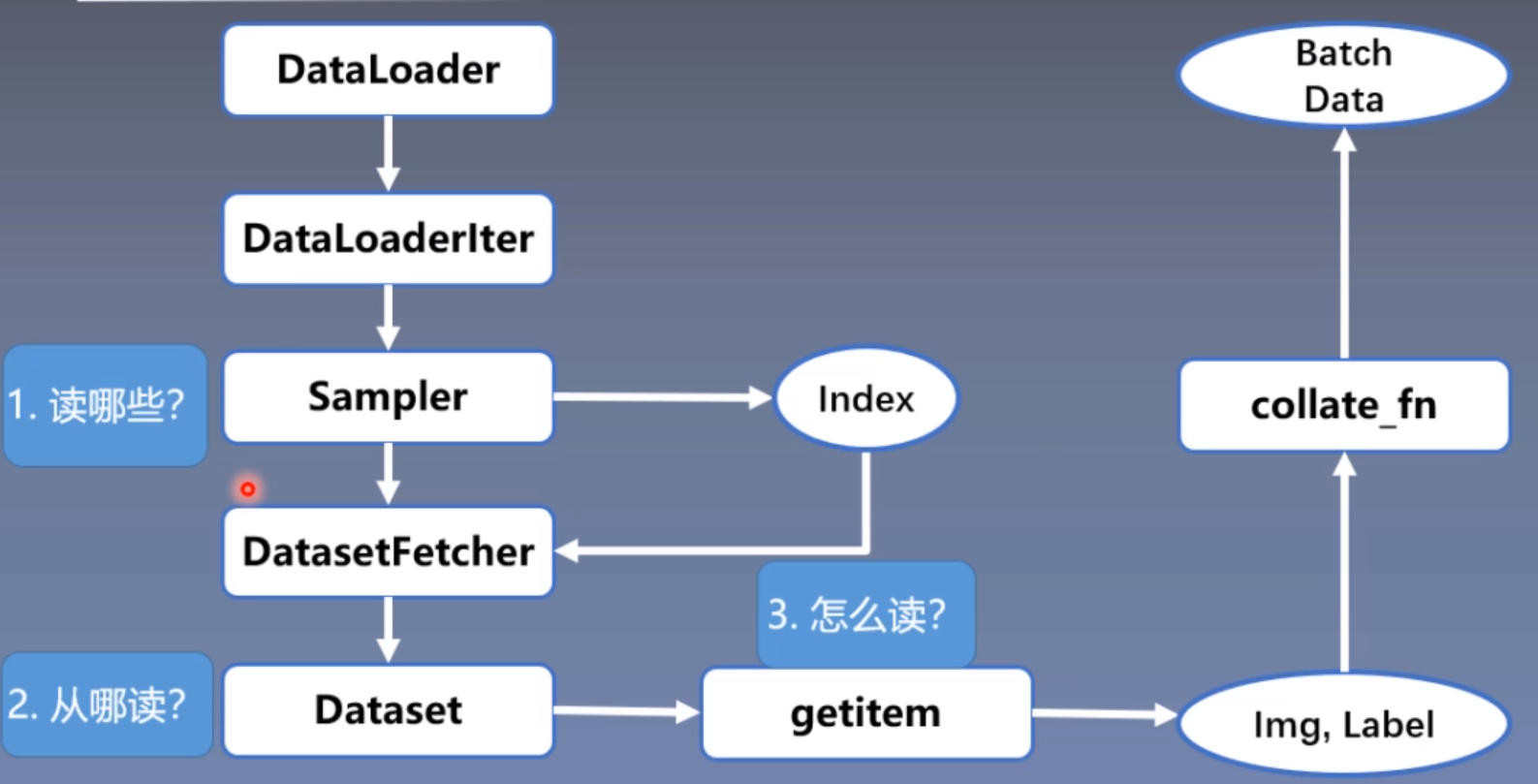
详细过程如下描述:
首先进入for循环
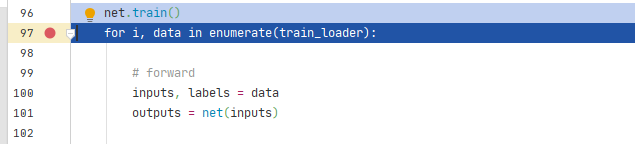
判断单进程还是多进程,程序中使用的单进程,因此进入_SingleProcessDataLoaderIter

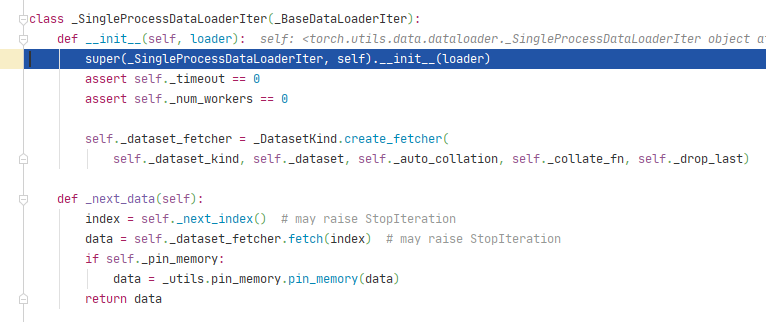
初始化_SingleProcessDataLoaderIter类之后,跳转到了DataLoader的__next__()方法。
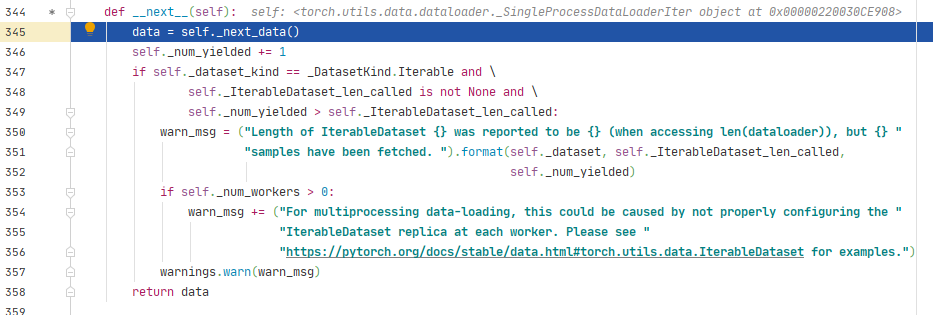
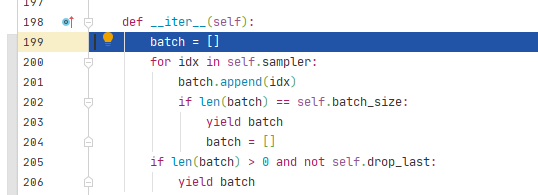
跳转到_SingleProcessDataLoaderIter类的_next_data()方法,其中_next_index()方法会调用Sampler类的__iter__()方法,用来读取index列表。
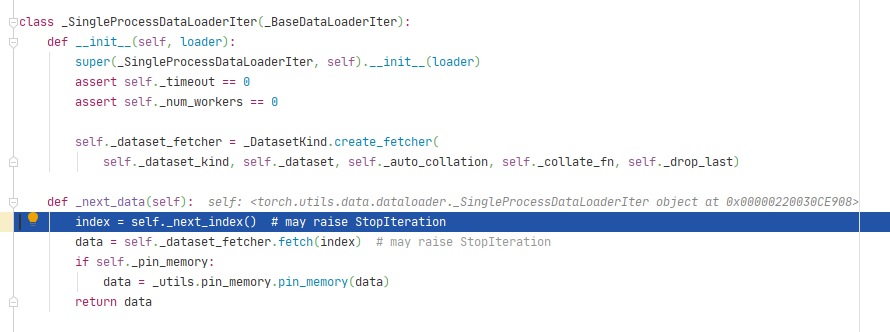

将index列表输入到DatasetFetcher类中,通过dataset[idx]获取图片和标签,dataset[idx]会调用Dataset的__getitem__()方法。我们在RMBDataset中已经写好了从硬盘读取图片和标签的代码。data是由一个batch的(图片,标签)列表组成。

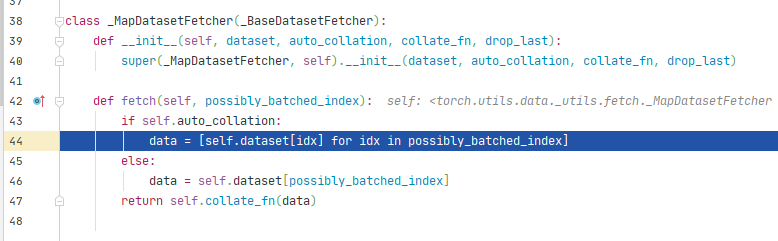

data在经过collate_fn处理后,转变为两个列表,分别是图片列表和标签列表