摘要
尽管神经网络在不同的应用领域已经取得了巨大的成功,但事实证明,它们容易受到对手的干扰(输入的微小变化),从而导致产生错误的输出。本文提出了一种基于梯度投影的文本通用对抗性扰动生成方法,即在任意输入端加入一系列单词,以大概率愚弄分类器。我们观察到文本分类器很容易受到这样的干扰:即使在每个输入序列的开头插入一个敌对的单词,其准确性也会从93%下降到50%。
介绍
近年来,神经网络在视觉[1,2,3]、语音[4,5,6]和文本[7,8,9]等领域得到了成功的应用。然而,有研究表明,神经网络容易受到输入的微小变化,即所谓的对抗性扰动的影响,从而导致它们产生错误的输出[10]。在实际应用中,为了保证网络在最坏情况下的性能,必须考虑网络对这种扰动的鲁棒性。在过去的几年中,许多研究集中在为图像数据设计对抗性扰动,以及防御和分析深网络对此类扰动的鲁棒性上[11,12,13,14]。然而,对文本数据的研究却很少。文本和图像的一个关键区别是文字和字符构造文本的离散性,这需要离散的优化方法来为它们制造对抗性的扰动
与图像设置不同,在图像设置中,我们可以使用输出的梯度来查找对抗性扰动,但未定义相对于单词或字符的输出梯度。然而,当单词或字符位于欧几里德空间时,可以计算它们嵌入的梯度。因此,Papernot等人。[15] 提出了一种通过将序列中随机选择的单词替换为与嵌入相关的梯度方向上最近的单词来愚弄文本分类器的方法。该方法基于快速梯度符号法[12],该方法通过计算相对于输入的梯度符号来发现扰动。在[16,17,18]中,相对于输入的损失梯度用于发现每个输入样本中的关键单词或字符,然后对它们进行扰动。Yang等人。[19] 提出了一个最大化敌方攻击成功概率的概率框架。他们的框架包括两个步骤:首先找到k个最重要的单词位置,然后选择位于这些位置的最佳单词,以最大化对手成功的概率。Alzantot等人。[20] 提出了一种使用语义相似的词来改变单词的方法和一种在该上下文中选择最自然的词的语言模型。Jia等人。[21]提出了一种将对抗句串接到原文中以欺骗阅读理解网络的方法。他们还引入了一个独立于模型的对手,在所有输入段落中添加一个随机有效句子。
Moosavi Dezwooli等人。[22]证明了图像分类任务中存在与输入无关的扰动,称为通用对抗扰动(UAP)。与对抗性扰动不同,uap是独立于数据的,可以添加到任何输入中,以便以高置信度欺骗分类器。同样,在本文中,我们提出了一种新的方法来产生文本数据的普遍对抗性扰动,因为它们可以插入到任何输入序列中,以愚弄给定的文本分类模型。与以前攻击文本分类器的工作不同,我们的攻击不需要分别优化每个输入的扰动。相反,我们寻找可以应用于任何输入序列的扰动(从相应的域)。该方法使用基于迭代投影梯度的方法来寻找必须插入到输入序列中的单词序列。我们在三个基于RNN的体系结构和两个文本分类数据集上对我们的方法进行了评估,结果表明,所有的体系结构都很容易受到这种简单的扰动。据我们所知,我们是第一个介绍通用对抗性攻击的文本分类器。
问题陈述
在本节中,我们将形式化查找文本分类器在有目标攻击和无目标攻击情况下的通用对抗性示例的问题。有目标攻击是一种攻击,在这种攻击中,我们的目标是欺骗分类器,使其将一个对抗性示例分类到一个预先确定的目标类中,而不是将其分类为真正的类,而在无目标攻击中,目标只是更改正确的类。首先,我们将对抗性例子的定义推广到文本领域,然后将其与普遍攻击相结合来阐述我们的问题。
文本的对抗样本
考虑一个分类器$f$,它将输入$\ x\in X$映射到它的类标签$\ l \in L$上。我们称$\ x’$为一个由$\ f(x) \neq f(x’)$构建的对抗性示例,而$\ x$和$\ x’$被人类观察者视为来自同一个类。设$\ x=x_1 x_2 … x_n$是$\ f$的输入序列,$\ x$是由文本数据的单词或字符构成的有序列表。我们现在可以通过在$\ x$中插入、更改或删除一些单词和字符来创建一个对抗序列$\ x’=x’_1 x’_2 … x’_n$
文本的通用扰动
在通用对抗攻击机制[22]中,我们寻找可以添加到每个输入样本的单个扰动,并以高概率愚弄给定的分类器。在这项工作中,我们证明了文本分类任务存在这样的普遍扰动。特别是,我们希望找到一个单词序列$\ w$,它通过与来自数据分布$\ P(X)$的任何输入样本连接,以高概率愚弄分类器
考虑一个输入$x$输出$l$的文本分类器。进一步,设$w=w_1w_2…w_m$为对抗性序列。我们构造了如下的对抗性输入,其中$\oplus$是插入算子,$k$表示从$0$到$n$的插入位置:
为了设计$w$,针对无目标攻击,我们针对真实类别最大化了分类器的损失函数。 我们的目标是将分类器转移到除真实分类器之外的任何其他分类上。 将$loss(l;f(x))$视为将输入$x$分类到$f(x)$类(这是分类器的输出)而不是正确标签$l$的成本,我们可以将$w$设计为:
如果我们想要执行一个有目标的攻击,我们打算将样本$x’$分类到一个指定的类$l’$,那么应该解决以下优化问题:
由于我们正在优化有关数据分布的预期损失,因此理想情况下,所得序列$w$是通用的。 即,当$\hat{w}$连接到任何来自$P(X)$的样本时,平均损失最大/最小
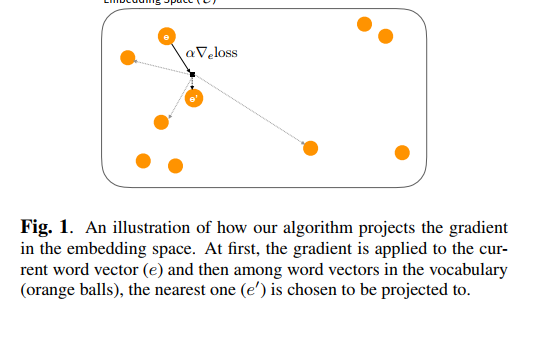
Fig.1 演示了我们的算法如何在嵌入空间中投影梯度。首先,将梯度应用于当前单词向量($e$),然后在词汇表中的单词向量(橙色球)中,选择最近的一个($e’$)投影到
对抗攻击算法
在本节中,我们描述了我们解决Eq.(2)和Eq.(3)中的优化问题的方法。由于文本数据的离散性,我们面对的是一个离散的优化问题。因此,用于攻击图像分类器的方法不能在这里直接应用。
为了在计算空间中表示单词,我们必须将它们编码成向量。我们把编码词的向量空间称为嵌入空间,把$V$看作我们的词汇表,它是一个有限的词集, 看作的离散子空间,其中$V$中的词被嵌入。同时,将$w$作为嵌入空间中的一个词向量,根据攻击是有目标的还是无目标的,我们现在提出使用梯度下降/上升来解决等式(2)和等式(3)中的优化问题。
在梯度下降/上升的每次迭代中,我们要添加到序列中的单词对应的嵌入向量首先使用梯度向量在连续嵌入空间中更新。形式上,对于$w$中, 我们计算输入样本$x$的下降/上升方向,其中,作为;其中 是的相应嵌入,$l$是正确的/目标标签(无目标攻击时,$l$是正确的标签。有目标攻击时,$l$是目标标签)。然后将得到的向量投影到该空间中的词汇向量()。独立地对每个字向量执行该投影,并且根据余弦相似度,投影到中的最近向量(如图1所示)。因此,
为了使无目标攻击中的损失函数最大化(式(2)),我们必须朝着比率α为正的梯度(梯度上升)方向移动。相反,对于有目标攻击(式(3)),我们将α设为负值,以便在梯度(梯度下降)的相反方向移动,以最小化损失函数。算法1总结了我们提出的方法。它还可以应用于经过少量修改的成批数据

实验结果
在本节中,我们将解释如何在不同的设置上设置和评估我们的方法。
设置
数据,我们在两个数据集上对我们的方法进行评估,以完成文本分类的任务。
•AG新闻数据集:我们实验使用的默认数据集是[7]提供的版本,其中收集了来自4个常见新闻类别(World、Business、Sports、Sci/Tech)的3000个样本。也有每个类1900个测试样本。
•Stanford Sentiment Treebank:这个数据集[23]包含大约11000个用于情绪分析任务的标记句。这些句子被分成五类,从非常消极的(1)到非常积极的(5)。
架构,使用长短时记忆(LSTM)单元[24]的基于rnnbased的架构被用作文本分类器。为了将网络的输入映射到连续空间,还对网络的输入应用了嵌入层。我们使用[25]提供的预先训练好的嵌入向量。所研究的架构如下:
•LSTM:默认使用的架构是带有LSTM单元的普通RNN。最后一个隐藏状态被提供给一个完全连接的层来产生结果
•bi-LSTM:我们还尝试了一个双向LSTM[26],其中两个方向的最后隐藏状态被连接起来并提供给下一层。
•mean-LSTM:我们在所有LSTM单元的输出上使用了一个平均值层,然后将它们提供给下一层。
超参数,所有LSTM单元都有512个隐藏单元。我们还发现学习率1是在嵌入空间中在词汇的词向量之间移动的合适值。Adam优化器[27]用于优化损失函数。
表现
无目标攻击,为了执行这种攻击,我们在等式(2)中解决了优化问题。表1显示了攻击LSTM的结果,通过将对手词连接到输入的开头来对新闻文章进行分类。有趣的是,在所有的实验中都存在一个占主导地位的类别,即科技类。这种攻击会导致可能达到的最小精度(即0.25%。随着对抗词数量的增加,模型的准确性下降,因为词的数量直接影响分类器的决策。根据这些实验,当一个单词被插入到任何序列的开头时,它可以将模型的精确度降低到50%
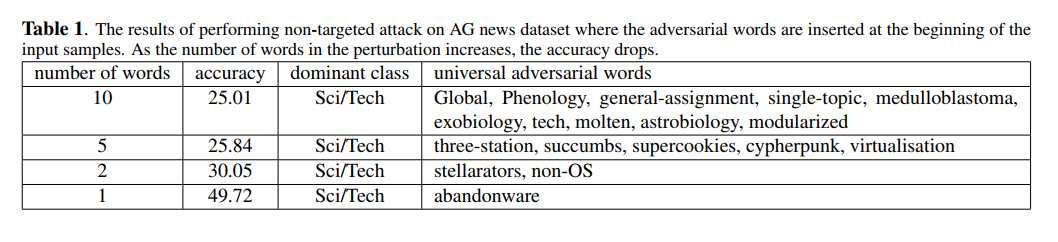
我们对在AG新闻数据集上训练的三种不同的体系结构进行了无目标攻击,并将对手词连接到每个输入样本的开头。结果见表2。所有的架构似乎都容易受到我们的攻击,这表明我们的攻击通常是对基于RNN的架构的威胁。
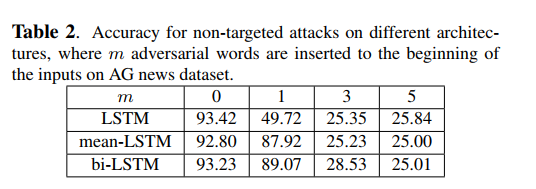
为了保证该方法的有效性,我们在另一个数据集(斯坦福情绪树库)上进行了实验,同时在LSTM模型的序列开始处插入了敌对词。如图2所示,该数据集也容易受到我们的攻击,并且几乎达到了可能的最低精度(即20%)。与AG新闻数据集类似,插入一个通用单词会极大地分散分类器的注意力。
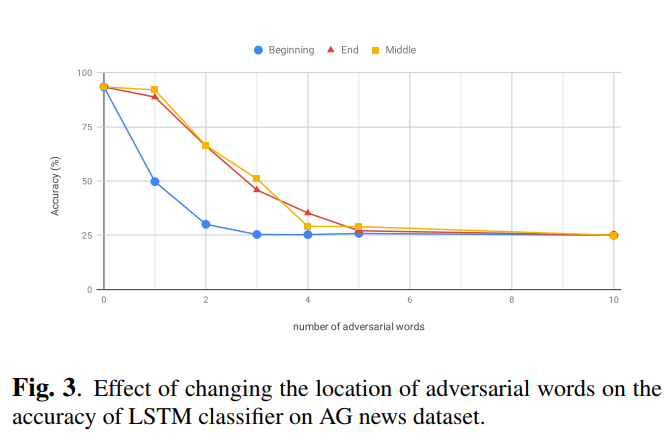
此外,改变插入字的位置的效果如图3所示。攻击是在AG新闻数据集上训练的LSTM模型上进行的。当单词被插入到输入序列的开头时,模型更容易被愚弄。该模型似乎更重视输入序列的开头。
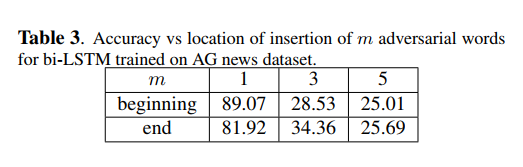
为了进一步研究它,我们对一个不确定输入序列方向的双向LSTM模型进行了同样的实验(表3)。可以看出,双向LSTM表现出更一致的行为(从双向LSTM可以看出,在首端和末端插入单词的最终效果没有很大区别)
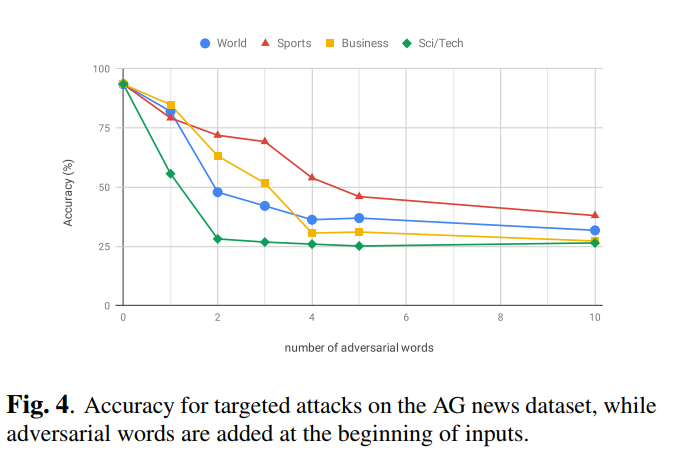
有目标攻击 我们尝试优化公式(3)。为了执行有目标攻击,我们对在AG新闻数据集上训练的LSTM模型进行了有目标的攻击,在该词的开头插入了对抗性单词。 图4表明我们的方法可以成功地应用于这类攻击。 根据结果,似乎某些类在欺骗模型方面更强大,这可能是由它们中使用的特殊词引起的。 例如,Sci / Tech类别具有许多技术用语,在其他类别中很少使用,因此,通过将它们插入任何句子中,分类器很可能被欺骗。
为了证明我们的攻击是有效的,我们从词汇表中随机选择单词插入到序列的开头,类似于Jia等人。[21]建议用于阅读理解系统。我们发现我们的模型对这种随机扰动几乎是鲁棒的,精度下降可以忽略不计;特别是,5个随机词导致精度下降仅5%。
结论
本文提出了一种通用的文本分类器攻击方法。我们提出了一种基于梯度投影的方法来制作与数据无关的对抗序列,当将其添加到任何输入样本中时,它很容易欺骗分类器。 我们在不同环境下评估了我们的攻击,结果表明,即使在如此简单的情况下,分类器也非常脆弱,以至于插入一个单词就会使分类器的准确性从93%降至50%。
由于文本数据的离散性,使得文本分类器的鲁棒性问题没有得到很好的研究,这比通常研究的图像数据带来了更多的挑战。在这种情况下还有很多问题没有解决,例如,注意力机制(Attention)如何影响模型的健壮性,可以在以后的工作中进行研究。
缺点:
1、 添加的单词之间没有任何联系,比较突兀
2、 通用扰动的扰动成功率较低

